UPDATE 시 어디에 INDEX 있고 없는 것이 성능에 좋을까?
| SET절에 INDEX O | SET절에 INDEX X | |
| WHERE절에 INDEX O | BEST | |
| WHERE 절에 INDEX X | WORST |
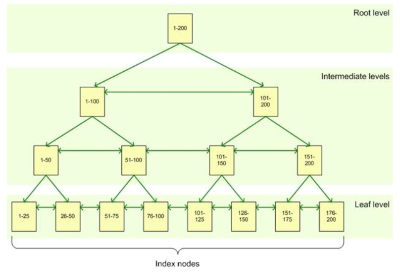
NON-CLUSTERED INDEX (NC)
=> LEAF LEVEL 은 NC에만 있음
=> INDEX "INCLUDE" 는 LEAF LEVEL에만 존재함
각 데이터를 인덱스 해놓음 ( 몇 페이지의 몇번째 )
(SEEK) 데이터를 찾을 때 이 인덱싱 트리에서 몇 페이지에 있는지 LEAF LEVEL 까지 찾고 (예: I/O 4)
(LOOK UP) 그 페이지 찾아가 실 데이터를 찾는다. (I/O 1)
(SCAN) 트리가 아니라 한 레벨 다 훑는것
2% 미만 데이터 검색할 때만 만든다.
2% 넘어가면 쿼리 돌릴때 알아서 인덱스를 쓰지 않는다.
[문제] 아래 쿼리들이 있을 때 어떻게 인덱스를 걸어야 하나?
| WHERE 조건 | 전체 쿼리 포함된 정도 | 검색되는 데이터 |
| WHERE A = 5 | 10% | 1.9% |
| WHERE B = 3 | 10% | 1.8% |
| WHERE A = 5 AND B = 3 | 80% | 0.9% |
[답] INDEX(B,A) , INDEX(A)
=> 포함된 정도가 높은 WHERE A AND B 쿼리에서 사용되는 인덱스를 거는 것이 좋다. 조금이나마 빠르기 위해 B를 앞에 걸어주고,
A 역시 전체 데이터에서 2%가 넘어가지 않으므로 A 인덱스도 별도로 걸어준다.
[문제2] 인덱싱 어떻게?
| WHERE 조건 | 전체 쿼리 포함된 정도 | 검색되는 데이터 |
| WHERE A = 5 | 10% | 3% |
| WHERE B = 3 | 10% | 1.8% |
| WHERE A = 5 AND B = 3 | 80% | 0.9% |
[답] INDEX(B,A)
=> (A는 전체 데이터에 3%가 넘어가므로 인덱스 거는 것이 의미 없다)
=> (B,A) 걸면 (B) 거는건 의미 없다
[참고]
> 범위 인덱스 (날짜)는 복합 인덱스시 앞에 거는 것이 좋음. 그래서 테이블 설계시 앞 열에 위치하는 듯?-?
> 시,군,구,동,건물 / 책 대분류~소분류 => 복합인덱스는 소분류부터 거는 것이 좋음. 다 아니고 2,3개만 거는게 좋음. (INDEX(건물, 동))
> CL의 경우 반대로 대중소로 검
CLUSTERED INDEX (CL)
LOOK UP 없음

기존 페이지를 전부 삭제하고 데이터를 전부 정렬시켜 인덱스를 거는 것
CLUSTERED INDEX만 있으면 SELECT COUNT(*) 하면 TABLE FULL SCAN 하는 것임
| MEMBER_ID | FIRST_NAME | MIDDLE_NAME | LAST_NAME | ... | |
| 1 | PARK | MM | JJ | ... | |
| 2 | KIM | (NULL) | GG |
COUNT(*) => ALL
COUNT(MEMBER_ID) => ALL
COUNT(MIDDLE_NAME) => X
COUNT할 때 NULL 허용되는 COLUMN 하면 낭패. * 로 COUNT 하는 것이 안전하다.
통계
20% 데이터 초과 업데이트시 통계 테이블 자동 업데이트.
(수동) PDATE STATISTICS [TABLE];
JOIN
> WHERE 절에 AND 붙이면 성능 좋아짐. 대신 IN 은 아님 (OR 절로 치환됨)
> FROM [TABLE] WITH (INDEX(0)) <= INDEX(0)은 테이블 그 자체임. 강제로 테이블 전체 스캔하라고 하는 것.
> INDEX(1)은 클러스터 인덱스
> WHERE SALARY != 3000 <= 부정문은 INDEX 못씀
> WHERE KEYWORD = '2' <= KEYWORD 가 CHAR / INDEX 걸려 있을 경우 INDEX 사용
> WHERE KEYWORD = 2 <= INDEX 사용 못함.
CHAR보다 INT가 우선순위 높아서 CONVER(INT, KEYWORD)=2 로 치환하기 때문
> WHERE AMOUNT < 변수 (EX: @X, SQRT(3)) 일 경우 계산 더 오래 걸림.
HASH JOIN : 테이블 크고 인덱스 없을때
LOOP JOIN : 테이블 작고 인덱스 있을때 ( where 조건 걸려 있을때 )
MERGE JOIN : 조인키로 정렬되고, 다대다가 아닐때 걸림. CLUSTERED INDEX를 유니크하게 줘야됨
부모 - 자식간 테이블에서 일어남

MERGE JOIN 제일 빠름 . 그다음이 HASH, LOOP

